
The Politics of Feedback in Software Development
Introduction
As we've discussed previously, all systems are built on abstractions, and all abstractions are at least a little bit wrong. The more complex and important a system is, the more likely it is that a leaky abstraction will gum up the works. So systems need feedback mechanisms to detect when an abstraction is leaking, so they can identify and fix the problem.
Unfortunately, feedback mechanisms are themselves systems which can be quite flawed. A previous post discussed five common problems with feedback mechanisms. A more general issue is that feedback mechanisms are influenced by the power relationships of the people giving and receiving feedback. Systems often get into vicious cycles where less powerful people are forced to absorb and adapt to problems, a process I call interpretive labor. These less powerful people are also less likely to be listened to by those with the power to change the system. So any feedback about the interpretive labor they're doing is lost.
I want to make all this a little more concrete by exploring a specific domain: software development. This is my field, so I can speak with some familiarity, but I am also just a single person. So this will still be a very incomplete sketch full of inaccuracies and over-generalizations.
In my last post, I discussed how digital technologies allow for great distances between actor and acted upon. This freedom from physical constraint gives computers incredible flexibility, but it also increases the likelihood of errors. Physical constraint is a natural feedback mechanism. Over the kinds of distances created by digital technologies, feedback mechanisms are not naturally occurring but instead must be consciously put into place.
Those who want to create software are thus starting with two strikes against them: the general tendency of people in power to marginalize those best able to give them feedback, and the particular nature of software development where feedback is 'off by default'.
Given this, it's surprising that software development has any functional feedback mechanisms at all! But it's a big field and there are many organizations that are trundling along.
This post will be focused on walking through a "typical" example of software development, and the most common feedback mechanisms and feedback dysfunctions to be found there. A follow-up post will explore some less common kinds of feedback patterns, including both the relatively utopian and the positively dystopian.
I have chosen, a little arbitrarily, to categorize the factors influencing software development into five levels:
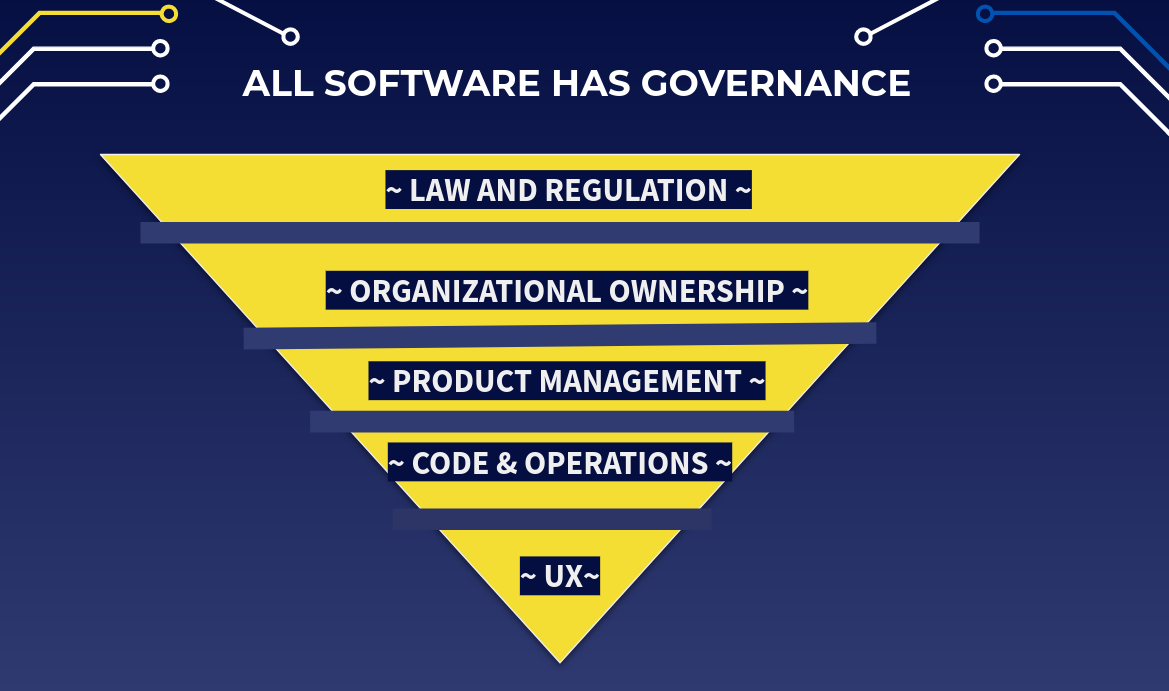
Each level is influenced but not fully controlled by the level above it. For instance, product management influences code, and code influences the user experience. Ideally, feedback also flows in the other direction. You don't just want code to influence user experience, you want user experience to influence code. But a poorly designed or authoritarian structure will often discard information from below.
The levels are:
- User Experience ("UX"): that is, the user's actual experience of the software in question, whether good or bad.
- Code and Operations: that is, the software itself, with all its embedded design decisions, bugs, features, etc. as well as the processes that keep it running, including user-facing support workers.
- Product Management: that is, the process by which the code and infrastructure is developed and the 'ideal' user experience designed.
- Organizational Ownership: the legal forms and practical processes that control the organization which is developing the software.
- Law and Regulation: the society-wide rules which ban, discourage, or promote certain kinds of ownership types, software features, behaviors, etc.
We're going to start at the bottom of the pyramid with a practical example, and work our way up.
Level 1: User Experience
Imagine you're a user trying to create an account on a website that will help you file your taxes.
The sign up form is straightforward. It asks for your name, date of birth, an email, and a password. The designers of the form have even provided some tools to help you pick a secure password, use the right formatting for the date of birth and email, and so on. They help guide you to submit valid data.
But who decides what's valid? I've got a hyphenated last name, and every couple months I get told by a website or app that my name is invalid. I am not the only one. There is a famous article Falsehoods Programmers Believe About Names which lists a bunch of incorrect assumptions about names often built into software. (See also Falsehoods Programmers Believe About Time and Falsehoods Programmers Believe About Addresses, among others.)
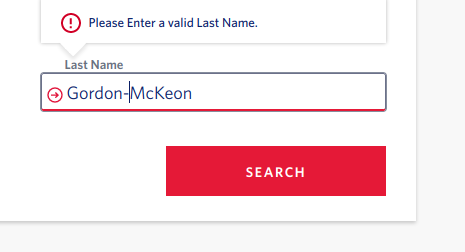
This is an example of what Olia Lialina calls "scripting the user" - that is, guiding the user to do what the designer has decided they should do. The designers have decided that users don't have hyphenated last names and have designed the system so that I must conform to this assumption in order to continue.
Typically I do conform. I don't care if some random website gets my name incorrect. But this website is for filing my taxes. Accuracy seems important. So I decide to report the problem, which brings us to the next level of the pyramid.
Level 2: Code and Operations
"Code and operations" includes all the infrastructure that directly creates the user experience, such as the software itself and the user support teams that help users navigate it. This level interacts constantly with the user, and correspondingly has access to a tremendous amount of information about whether the system is working for users.
Unfortunately, organizations seldom make effective use of this information. Sometimes they simply haven't bothered to gather it. Sometimes they are more focused on collecting demographic and consumer data about users. (This is closely tied to the logics of surveillance capitalism, which we'll come back to later.)
It's at this level the form's inability to process hyphens is instantiated. Somewhere, a piece of code is checking that names are made up only of letters. As a user, I have no way to see the code, let alone change it. So I decide to 'contact support' to report the problem. When I do, a little chat box pops up. A cheery avatar tells me their name is Natalie and asks me what my issue is.
On the internet, nobody knows you're a dog. Is Natalie a dog, or an AI, or a human? If she's a human, is she a full-time employee of the company who is empowered to share issues with the designers? Or is she siloed away in an off-site help center?
"The feedback form doesn't accept hyphens," I tell Natalie, "and my name has a hyphen."
"I'm sorry," Natalie responds. "I don't understand. Can you tell me more about your issue?"
I try again: "I'm getting a message that says the name I entered is invalid, and I'm pretty sure it's because of the hyphen. But this is for my taxes. Shouldn't I be using my exact legal name?"
There's a long pause. Maybe Natalie is thinking this through. Or maybe the system is busy passing control from the AI to an actual human.
Regardless, there's little chance that she can actually resolve my issue. Perhaps the company has confirmed with the IRS that errors like these won't cause tax filings to be rejected. Perhaps there's an item in her FAQ that says, "Users with hyphens in their names should replace them with spaces". But more likely, the company doesn't know that the problem exists - or they do know, but they haven't prioritized fixing it. In which case, there's not much Natalie can do.
"Can you submit this as an issue to the development team?" I ask Natalie.
"Of course!" she responds.
This is where I, as the user, lose any visibility into how this company's feedback mechanisms work. Companies may follow up on user support requests, but they almost never loop those users into the product development process.
But you and I can follow my complaint to the next level: product management.
Level 3: Product Management
Product management is where most software design decisions get made. I'm going to describe a lightweight, agile development process that is fairly common in the software industry, though of course there are many alternatives and bigger companies tend to use more elaborate systems.
Many software companies use two distinct "ticketing" systems to track the support requests coming in from users and the work items (bug reports, feature requests, etc) being assigned to the development teams. But how does a support ticket become a development ticket?
Some companies have no process for this at all. A company that devalues user support and seeks to provide it as cheaply as possible—through understaffing, low wages, contracting out support roles, isolating support staff from their higher-paid development teams, or even replacing support staff with AI—is unlikely to see them as having important information to share.
An informal survey of my friends found that a distressingly large number of companies have no formal process for support staff to create development tickets. But they also mentioned outliers, like an organization where support staff were invited to weekly developer meetings, and another where product managers worked with user support teams to proactively identify patterns of user needs and complaints.
Let's say that our fictional tax prep company falls somewhere in the middle. They don't actively bring support staff into the development workflow, but they do allow user support staff to put the occasional user ticket, or collection of tickets, into the development team's queue.
Unfortunately, as anyone who's ever surveyed a 500-issue backlog with mounting despair can tell you, not every ticket in the queue will be addressed.
One challenge when tackling tickets is that crucial information about the problem is often not included. Software works differently on different devices, so developers need to know what devices and/or browsers (and what version) the user was on. They also need to know what the user expected and what actually happened, and the difference between the two. That is, they need to know the local context.
If the user support person fails to gather the right information, the user request is dead in the water. For instance, if Natalie had simply written, "The user's name is being rejected as 'invalid'" the development team wouldn't know the issue was with hyphens specifically. I'd know, but they have no way of following up with me.
But let's assume the development team has enough information. The ticket will still not be addressed unless it is prioritized. So how are decisions about priority made?
One common process is for executives and directors to hand down high level objectives. Leaders may set goals like "increase revenue by 10%", "expand into X market segment" or "improve reliability". Teams will then take these goals and break them down into smaller and smaller units of work, such as projects, milestones, and/or epics.
Let's say one of the leaders has picked a goal "increase diversity of user base". A development team might then create an epic "remove barriers that disproportionately effect non-white ethnicities". They would then go through the backlog looking for tasks that fit this epic, and might find mine sitting around. (I am white, but issues with names including unusual characters tend to disproportionately affect people of color.)
Months or years after I reported the issue, the development team fixes it—for me, at least. (They may still encode other assumptions about names into their system.) But I never find out. I have moved onto a different app, in the perhaps vain hope of finding one that better handles user feedback.
Level 4: Organizational Ownership
How product development is done—what processes are used, what priorities are set, etc—is determined by the organization's structure.
Much software is developed by business corporations, which are authoritarian in form. They provide limited legal avenues for users, workers, and other stakeholders to influence the decision-making process. Despite the fact that they almost always have a much richer understanding of the software—its flaws and benefits, its risks and potentialities—they are only involved when the leadership team has the good sense to welcome them in. This almost never happens.
Leadership instead focuses on pleasing shareholders. In some cases, leadership is the shareholders. Elon Musk is currently giving a very public demonstration of the risks of this organizational model. Because Musk is now the main shareholder of Twitter, he is strongly incentivized to wring profit out of the company, and is making top-down product decisions that ignore the feedback of most users and most internal workers such as product managers. It's not going great.
Other companies have more passive shareholders. Many shareholders are so passive they don't even know they're shareholders! Nearly 150 million Americans own stock, most of which is index funds. (Index funds combine small amounts of stock from a large number of companies, which makes it hard for people to know what they've invested in.)
Regardless of how involved the shareholders are, in most cases decisions are made by them or on their behalf—not by the people who actually use or build the product.
This makes any good feedback mechanisms within the organization inherently fragile. Often they are set up by lower-level employees and may degrade or disappear once those people move on. Sometimes good feedback practices are set up by high level executives, but this is driven by self-interest. Amazon has long claimed to have a "customer-first" approach which takes customer feedback seriously, but as Amazon's market dominance has intensified, user experience has declined.
There are alternatives to for-profit corporations. Software can be built by non-profits, universities, government agencies, worker cooperatives, or even by informal open source communities. But even this does not necessarily avoid authoritarianism. Most non-profits use self-perpetuating rather than member-elected boards, cultivating a top-down power structure. And many open source projects adopt a "Benevolent Dictator for Life" model.
Why is it so rare for stakeholders to have a real say in how software is developed? To answer this question, we must go to the bottom, foundational level of our pyramid—the laws and regulations of society as a whole.
Level 5: Law and Regulation
There are many different bodies of US law which impact software development, including corporate law, contract law, antitrust law, securities law, bankruptcy law, and consumer protection law, just to name a few. A full discussion wouldn't fit in a library, let alone a book or a blog post. We must restrict ourselves to a few shallow examples.
How the Law Shapes Organizational Ownership
Corporations are fundamental to modern economic life, but it hasn't always been this way. Corporations used to be created only by an act of the legislature, and typically required some kind of overriding public benefit. Over time, thanks to various laws and Supreme Court decisions, corporations have become much more profit-driven and commonplace. They are the government's favored organizational form, given benefits not accessible to sole proprietorships and business partnerships. David Ciepley's Beyond Public and Private: Toward a Political Theory of the Corporation (one of my very favorite papers) explains this beautifully.
What the law gives, the law can take away. Elizabeth Warren's Accountable Capitalism Act, and Bernie Sanders' list of proposals from his Presidential run, give some concrete examples of how the government can change the kind of ownerships structures it encourages. These are only the tip of the iceberg, and quite modest compared to more radical proposals, but even just these changes would be transformative.
How the Law Shapes Product Management
After decades of worker unrest, and in the aftermath of the Great Depression, modern labor law was codified by the National Labor Relations Act of 1935 (later amended by the Taft-Hartley Act of 1947). The NLRA greatly strengthened protections for workers but it also shaped what kind of organizing and advocacy was seen as legitimate. Much organizing since then has focused on improving working conditions: better wages, safer workplaces, less harassment, and so forth.
The definition of "working conditions" has become narrow. Issues like workplace democracy, having a say in product design, or worrying that the software you're building harms people, tend not to fall under NLRB protection. Thus, workers who want to use their collective power to create better product management processes are on shakier legal ground than those advocating for higher wages. If the law were different, workers might be more empowered to push for better, more inclusive product management.
(That said: if you are a tech worker reading this, don't give up! The Bargaining for the Common Good movement supports workers who dream big, like the striking teachers who demanded affordable housing for their homeless students. Organizing doesn't need to be legal to be successful. See wildcat strike actions.)
How the Law Shapes User Experience
Law can shape software directly. Many websites have terms of service that users must agree to. There are legal limitations on the content we can upload to platforms. There are accessibility requirements.
Data collection is a particularly visible topic right now. While some projects commit to collecting no data at all, ad-supported behemoths like Facebook and Google collect as much data as they can.
Automated, invisible data surveillance doesn't just strip users of their right to privacy, it also takes the place of more participatory forms of feedback. Automated data collection presumes that the collector knows best which data to collect; that the collector's mental models are correct and can be used to make good sense of the data; that the kind of data that can be collected automatically and remotely is as useful as data which requires real conversations with users. This is very often not the case.
Laws on data collection thus not only impact the user experience, but how and whether user feedback is collected. Law doesn't just influence other levels, it influences the relationship between different levels.
Conclusion
This blog post is much longer than I originally intended! It focuses on a "typical" development workflow. But there are practices that can make feedback mechanisms significantly better or significantly worse. In part two, we'll dive into the good, the bad, and the ugly of feedback mechanisms in software development.
Member discussion