
How Feedback Loops and Interpretive Labor Help Us Develop Better Software
Information naturally flows from those who have more power to those who have less.
That is, some kinds of information do. Those who study surveillance capitalism or worker surveillance will rightfully point out that when there is money to be made from carefully watching those you have power over, information seems to flow the other way. But I am not tackling surveillance capitalism or worker surveillance in this post. Instead, I'm focusing on the specific kinds of information which emerge from imaginative labor and interpretive labor.
Imaginative labor is the work of imagining how the world could be, building models, theories, product designs and plans. Imaginative labor creates imaginative information—information about the model or plan to be implemented. Interpretive labor is the work of actually adapting a model, product or plan to reality, and it creates interpretive information—information about the gaps between model and reality.
This diagram shows what information flows might look like in a typical organization that develops software:
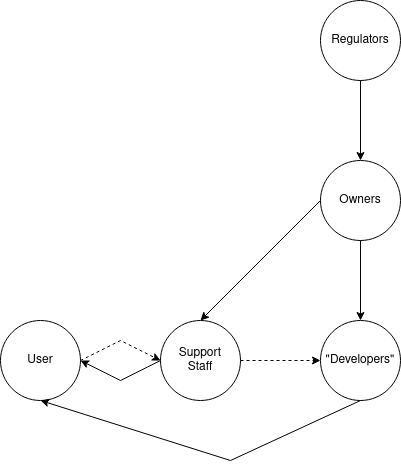
The diagram shows imaginative information as solid lines flowing from owners to their employees (developers and support staff) and from those who are designing and supporting the software to users. Developers (product managers, designers and engineers) send imaginative information to users through their decision decisions, while support staff send it through direct communication. Regulators send information to all parts of the system but tend to communicate most directly with organizational owners.
There are two dotted lines representing interpretive information. These flows happen against the power gradient and do not arise naturally, but must be constructed. Users are the primary performers of interpretive labor in software systems. I added flows of interpretive information from users to support staff, and support staff to developers, because many software companies will create at least minimal versions of these channels. For instance, some organizations allow support staff to create tickets for developers to consider, based on user feedback, as discussed in the previous post.
Some organizations do far better than this, creating many more channels for interpretive information to flow. Others are much worse, and actively try to suppress information.
In an ideal world, interpretive information is constantly incorporated into subsequent imaginative labor. The model is adjusted to fit reality. But, in hierarchical systems, this doesn't happen naturally. Instead, those at the top perform imaginative labor and pass the resulting imaginative information down through communication channels greased by power. Meanwhile, those at the bottom perform interpretive labor, adapting the model to reality, with no way to share the resulting interpretive information back to decision-makers high in the hierarchy.
This post will discuss the ways we can do better—the ideal world. A follow-up post will describe all the ways things can go terribly wrong.
What is the ideal which we are aiming for? I define "utopian" software as that which meets the needs of its users as effectively as possible, while minimizing any harms to users and non-users. Because users are best positioned to know their needs and to understand the harms they're experiencing, ideal software development highly values user feedback and is careful to incorporate it into every level of development. To use the terminology introduced above, ideal software development incorporates interpretive information into decision-making processes at all levels.
The rest of this post is a list of best practices which, if combined, bring us closer to our ideal system. I have ordered them from the smallest scope to the broadest.
I will be talking about open source a lot, so I want to define it before we begin. Open source software is software for which the source code is available and legal to copy, modify, and distribute. It can be achieved by simply posting your source code online along with an open source license, but it tends to come with a variety of best practices, which I'll cover in this essay. Doing the bare minimum is often derisively called "throwing it over the wall"—an evocative term with clear implication for how feedback flows in such a project. If software is not open source, it is "proprietary".
I've been an open source developer for over a decade, so it's probably not a surprise that my ideal software development process involves a lot of open source. But let me be clear: modern open source practices may be necessary to create functional information flows, but they are certainly not sufficient.
Dogfooding
"Dogfooding" is when designers and developers are also users of their project. For example, most developers of Python also use Python in their daily work, and according to several employees, Github is developed using Github tooling.
Dogfooding creates a short-cut in our information feedback loop. When people experiencing problems are also responsible for solving those problems, there's much less chance of information about the problems being lost. The needs of users are naturally represented in product decisions.
Of course, users are often diverse. Dogfooding surfaces and prioritizes the needs of developer-users, which may differ from non-developer-users.
Even developer-users may feel adrift if they are external developers. I've worked with several projects which originated as internal tools. When these projects were open sourced, other people and organizations adopted them and sought to contribute back. But these external contributors often struggled to advocate for themselves. Even though they were also developer-users, dogfooding didn't always help them, because their needs were different from the developer-users driving the project.
Still, it's a big red flag when a product is not being dogfooded. It not only signals a low quality product (like, why aren't the developers using it?) but also blocks a good and easy-to-access feedback source.
Done correctly, dogfooding makes our information diagram look like this:
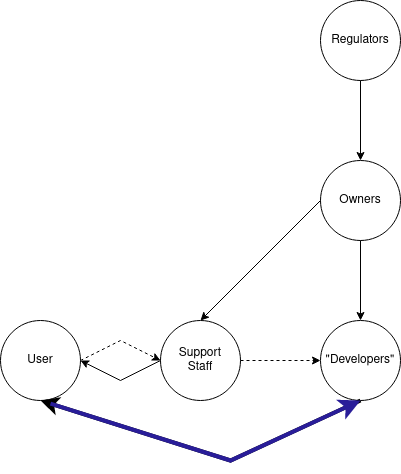
Instead of a one-way flow of information and power from developer to user, we now have at least some way for users to influence development, by virtue of being the developers.
Integrating Support Staff Into Product Development
Another way of getting information more directly from users to developers is to have developers regularly serve as support staff. For example, ActionKit requires its engineers to each spend one shift a week doing direct customer support. I've heard Automattic does something similar.
Open source projects often have maintainers in user support roles, usually because there's no one else to do it. This can be a real burden and lead to burnout, but for maintainers who can manage it, it's a great source of information about what is and isn't working.
A tech worker described to me a job they had where support staff were invited to standups ("standups" are daily/weekly meetings where the development team decides what to work on, called standups because they're meant to be quick). "They came only when they had something to discuss, generally a report or spate of related reports from users that suggested a change or new feature. Typically, we'd leave the meeting with a plan for one or more engineers to dig more deeply into the question and then work with product owners to figure out what should or should not be done. It just got the conversation started, which was all that was needed."
Other friends have seen support staff routed to user research specialists. When done poorly, this extra step can be a barrier to feedback, but in the best case scenario, specialists will be better able to elicit and contextualize information coming from users.
This intervention ideally creates a workflow that looks like this:
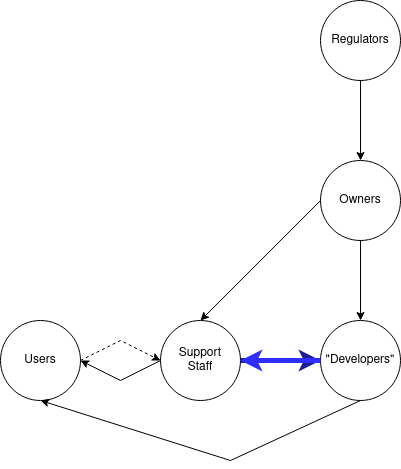
Public Issue Trackers
Public issue trackers are a place where developers, users and community members can report issues with the project and request enhancements. You can see an example here.
Public trackers allow users to communicate directly with developers and with each other. Not only can they send feedback, they can see whether the developer has received it by checking for replies. Trackers also provide space for further discussion and information-sharing.
That sounds great in theory, but there are some drawbacks in practice.
First, you need to be comfortable with issue trackers to take advantage of them. Trackers are designed for software developers and can be confusing to those unfamiliar with development practices—that is, most users. There are also a variety of norms around issue trackers, such as the expectation that users will check for duplicate issues before posting. This can be a daunting task. Trackers often have hundreds of issues with titles that seem like a foreign language. From the example above: "kwargs are not checked for unexpected parameters"—what non-developer would understand that?
Users may also be overwhelmed by the details trackers ask for. This often includes: (a) the behavior the user expected to see; (b) the behavior they got; (c) any errors messages that appeared; (d) the version number of the software; (e) the name and version number of the operating system and/or browser, if appropriate; (f) how important and/or urgent the issue is for the user. This is grade-a useful interpretive information! But it's not easy for most users to supply it. It's a kind of interpretive labor they've never had to perform before, and they usually need help.
In an ideal system, this is where user support staff come in. Instead of serving as a firewall, blocking the flow of feedback, staff would be trained to help move information. They could be the ones to merge duplicates, help users find version numbers, and set expectations regarding things like response times. Issue tracker tooling should also be redesigned to include interfaces for non-developer users.
In such a system, the core responsibility of user support staff would be to help users and developers communicate. The flow of information would look like this:
Another challenge with issue trackers is that they can grow unmanageable. Mastodon, for example, has 3500 open issues. But this problem occurs at much smaller scales. At some point efforts to prioritize and respond feel futile.
Repository hosts often provide project management tools to help with the overwhelm. However, many projects choose different, more fully featured tools. These tools are sometimes private and at the very least separate, making it hard to see how feedback is being used in decision-making.
Ideally, it would be possible to track the flows of feedback into decision-making seamlessly, but this is not just a tooling challenge: it's a social one. We turn to this challenge in our next section.
Collective Technical Decision-Making
Technical decision-making is where we really start to involve the "owners". Of course, owners are responsible for everything in their organization, so in a sense they've always been involved, but with technical decision-making they begin to participate directly.
In most companies, high level goals come from the top down. These can be vague goals like "grow the userbase" or "increase engagement", or they can be more specific, but generally speaking they are not up for debate. This is a problem because, in most organizations, owners simply don't know enough to be making technical decisions; they are making them because they're empowered to, not because they ought to.
An ideal system would be driven not by owners but by those who have the interpretive information about how the software is actually functioning in reality: users, developers, and support staff.
Community Roadmapping
As an open source community manager, I have been trying out a process I call "community roadmapping". It's messy and imperfect, but it's my attempt to push us towards the ideal. Community roadmapping involves:
- inviting community members to participate, especially key stakeholders and underrepresented groups
- making myself available ahead of the roadmap to answer questions about the process and suss out potential conflicts
- a collaborative brainstorming session in which participants share their needs and build off each other's ideas
- a voting process where people indicate how important different items are to them, allowing collective priorities to emerge
- creating space for community-members to opt-in to tackling specific items or projects
This kind of roadmapping process then guides work on a daily basis. It's important to stay flexible—a critical bugfix shouldn't be rejected because it's not on the roadmap—but having a community consensus can help provide context to users when requests are deprioritized. "That's a great idea, but we're prioritizing [accessibility/reliability/technical debt] this quarter," a maintainer might say.
Of course, in open source, users don't have to wait for maintainers to make the changes they requested. If they have the capacity, they can make the change themselves. That's a big "if", though. Even skilled developers with plenty of free time may lack the project context they need to do the work. And when they do submit a pull request, existing maintainers may not have capacity to review the contribution. Review is often a time-consuming process, which is why pull requests can sit open for weeks, months, or even years. In an ideal system, capacity to mentor contributors and review their requests would not be a scarce resource.
Architectural Decision-Making
Some projects have created processes to handle architectural decisions. "Architectural" is a squishy term—it means something like "design decisions that affect the whole system, or large parts of the system". With a large project, architectural decisions can affect millions of people.
The Python programming language is just such a project. In 2000, the community created Python Enhancement Proposals (PEPs). PEP 1 outlines the process, which has changed over time. It currently involves discussing the idea publicly to get feedback, finding a sponsor among the core developer team, getting a draft PEP approved for discussion, discussing with the community and iterating on the PEP, and finally, submitting the PEP to Python's Steering Council.
Note that this process solicits feedback at several stages. Note also that the Steering Council is elected by the core developers, who themselves come from the community. It is a very community-driven process, one which is explicitly resistant to corporate capture.
PEPs are not a foolproof system, and they tend to be developer-centric. An ideal system would be more accessible to all users. Nevertheless, it is a significant step up from how technical decision-making is usually practiced.
When adopted, things like community roadmaps, well-resourced external pull requests, and PEPs make our diagram look something like this:
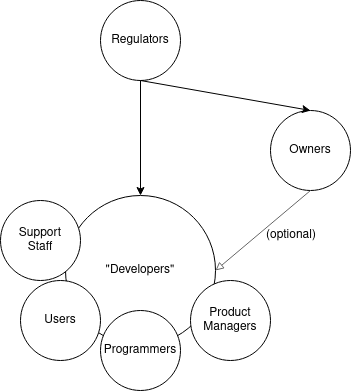
These tools allow all stakeholders to become "developers" in the sense that they are guiding development. Owners become optional: in the example of Python, there is no owner beyond the stakeholders.
Delegated Design
The bigger and more critical a project is, the harder it gets to engage in technical decision-making. More conflicts emerge, and the stakes are higher.
One approach is to avoid making decisions through delegated design. If the goal of collective technical decision-making is to bring stakeholders into the decision-making process, the goal of delegated design is to push decisions into the domain of individual stakeholders.
Imagine a site like Facebook or Twitter with a feed-style timeline. Some users might want an algorithmic timeline that shows the most popular posts first. Others might prefer a chronological timeline. We could bring all our users together to see which option has the most support. Or we can design our site so that each user gets to decide for themselves.
Website can also delegate decisions by allowing users to add code to the site itself. For example, this post is written on the Ghost newsletter platform, which allows users to add HTML, CSS and Javascript to posts.
Ghost also has an integration system. Integrations (sometimes called "plugins", "apps", "modules", "extensions" or "clients") allow external developers to contribute new features and designs. Some apps even provide full, alternative interfaces to websites, such as the Apollo client's alternative interface for Reddit or the Elk client's alternative interface for Mastodon.
These third party integrations are a form of interpretive labor that helps bridge the gap between the software as written and the needs of users. Ideally, information about these gaps is incorporated into the design of the core software, improving the overall user experience. Often, the reverse occurs, and third party integrations hide information about gaps from the main company. This is because users will just use the integrations rather than leave or complain. Reddit, having taken steps to close down the popular Apollo client, is discovering just how much interpretive labor that app was performing for them. I'll say more on that in the follow-up post on dystopian software development.
Apollo's fight with Reddit over API access brings up a key limitation of integration systems, and of most (all?) forms of delegated design: they are built around an application programming interface (API) which is designed and, in closed systems, operated, by the core project. If those designers choose not to include functionality in the API, there is often nothing integration developers can do.
APIs are a site of political contestation, with the APIs of major proprietary platforms subject to regulation and debate. In 2019, the FTC fined Facebook $5 billion for, among other things, providing too much access via its API. A year later, the FTC sued Facebook for depriving competitors of access to some of its APIs.
A map of an API like Facebook's might look like this:
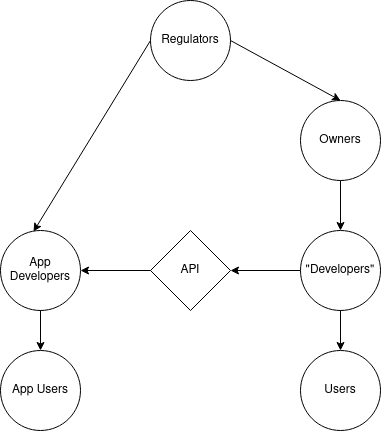
Users can choose an app with additional features, but their options are still fundamentally constrained by the core platform. An integration system is therefore not a complete delegation of design. Some design decisions remain centralized.
Federation
What about federation? Software federation is when platform developers agree to abide by a shared protocol that allows their users to interact. Email is a federated system; so is the internet itself.
Federation is the most extreme version of delegated design. Stakeholders share only a protocol—every other piece of functionality is delegated to the platform.
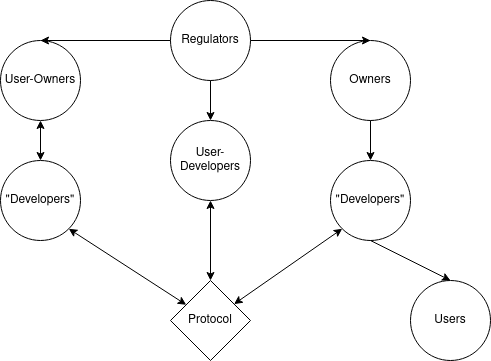
In a federated system, different organizations with different structures can participate. Collectively they determined the shared protocol; their behavior is also constrained by the protocol (hence the double-sided arrows).
Even here there is a subject for collective decision-making: the protocol. So there is no way to avoid the need for some kind of collective governance.
Furthermore, all systems face sociotechnical challenges that require coordination, such as protecting against malicious attacks, reputation management, and adjudication. These challenges are easier to handle in centralized systems; federated systems must proactively create methods for tackling these challenges, otherwise they face emergent centralization. (Email is a federated protocol, but 90% of all users are centralized on either Apple or Gmail. This re-centralization is partly due to the greater capital resources of big tech companies, but it also represents a failure of collective governance.)
So: while ideal software development should embrace delegated design, it sill requires collective governance, which we will discuss in the next section.
Organizational Governance
It is now time to focus our attention directly on the owners in our diagram. What are the legal rights and obligations of owners? How do these legal structure impact the flow of information? What would the ideal legal structure be?
As discussed previously, most software in the United States is owned by corporations, whether that's big for-profits like Google and Amazon, venture-funded startups, or non-profit corporations like universities. Corporations have a variety of legal privileges that make them immensely appealing as an organizational form, including the right to coordinate, the right to contractual unity, and the right to make and enforce rules. For-profit corporations have additional privileges which let them avoid many kinds of financial risk and responsibility.
Ownership of a corporation rests in the board of directors. (Some say that a corporation is owned by its shareholders; David Ciepley argues convincingly that corporations own themselves, and shareholder ownership is a legal fiction.) Regardless, boards can be populated in a few ways:
- In a for-profit, directors are elected by shareholders.
- In a non-profit, directors can be elected through some kind of membership structure (a "member-elected" board), or...
- In a non-profit, directors can also elect other directors (a "self-perpetuating" board).
- In a worker or multi-stakeholder cooperative, directors are elected by customizable membership classes such as workers, consumers, suppliers, or users.
Of these, the non-profit self-perpetuating board and the for-profit with majority shareholder tend to be authoritarian. It's unclear which is worse. US law requires nonprofits to be of public benefit, but in practice this is seldom enforced; on the other hand, the law with some frequency intervenes to protect the interests of minority shareholders. Regardless, either of these structures lends itself to systems where interpretive information is discarded and the ignorant drive decisions.
A for-profit with no controlling shareholder may be less authoritarian, but still tends to prioritize the needs of those with little to no knowledge of the system. While workers and users sometimes own shares in platforms, they usually aren't involved in governance. And many shareholders have no idea they're even shareholders.
This leaves two palatable (American, legal, single-corporation) organizational forms: member-elected non-profits, and cooperatives. Of course, there is a lot of flexibility in how these organizations are designed, and they could be designed quite badly. But let us imagine an ideal structure, one in which users, developers, and support staff are all guaranteed seats on the board:

In an ideal world, corporations probably wouldn't exist at all. But in our current world, either a multi-stakeholder cooperative or a member-elected non-profit is probably our best bet.
Regulating Better Software
The organizational forms described in the previous section were all created by government, and are regulated by government. The concept of corporate "ownership" is a creation of the state.
This fact has been obscured by the wealthy, who put a lot of effort into making capitalism seem natural and inevitable. Nevertheless, the relationship between regulation and ownership seems the most straightforward. It can be harder to see how regulation impacts developers, support staff, and users.
Three quick examples will showcase how regulation can be used to create better software by targeting these three groups.
Regulating Development
Most of us have learned to accept the sloppiest kinds of software development, but it doesn't have to be like this. An article from nearly 30 years ago describes how NASA wrote software with hundreds of thousands of lines of code and virtually no bugs (they averaged one bug per version):
NASA knows how good the software has to be. Before every flight, Ted Keller, the senior technical manager of the on-board shuttle group, flies to Florida where he signs a document certifying that the software will not endanger the shuttle. If Keller can’t go, a formal line of succession dictates who can sign in his place. Bill Pate, who’s worked on the space flight software over the last 22 years, says the group understands the stakes: “If the software isn’t perfect, some of the people we go to meetings with might die."
But NASA isn't no longer the only organization developing software with life and death stakes. Every major tech company has killed someone, whether it's the 17 people who've died due to Tesla's autopilot, Facebook's blind eye towards genocide, the black box algorithms that send people to prison, or errors in medical software. We don't demand the care and caution from them that we demand of NASA. But we could.
Similarly, we could demand that critical software be developed in ways that are open and accountable to users, that incorporates their feedback. Wouldn't that be something?
Regulating User Support
User support staff are some of the most exploited workers in the tech industry today. User support is frequently contracted out, treated as gig work, under-resourced and under-paid. Perhaps the most salient example of this are Facebook content moderators, who in 2021 won an $85 million settlement after over 10,000 moderators developed PTSD and other mental health issues as a result of working for Facebook.
The government could take more aggressive steps to prevent misclassification of contract workers, ensure safe working conditions, and protect union organizing efforts. They could also pass legislation further empowering workers. Empowering workers allows them to advocate not just for themselves but for users and for society as a whole. Nearly every problem at companies like Facebook noticed first by workers, who advocate for change but are often ignored, dismissed, or even fired. Protecting workers protects all of us.
Instead, companies seem to be leaping straight into replacing support staff with AI. But we'll save that for the post on dystopian software development.
Regulating User Experience
Finally, governments can and have regulated user experience. In Europe, General Data Protection Regulation (GDPR) guarantees certain user experiences which protect data privacy. There are also legal requirements for accessibility. While I am wary of government getting too invovled in the details of user experience, I think this general approach of affirming core values and mandating minimum standards could be very beneficial.
Other values that governments could affirm and protect, in addition to privacy and accessibility, include interoperability, transparency, customizability, and even governability.
Conclusion
If you've made it to the end of the essay, I'm so impressed! This ended up so much longer than I originally intended. My goal is to write much shorter and more frequent posts in the future.
In the next post(s) in this series, we will discuss the opposite of the ideal: dystopian development practices. In such systems, user feedback is minimized, and seldom influences product design or organizational goals. These systems may encourage information asymmetries, misinformation, and user "capture" (through monopolies, network effects, sunk costs, etc) that prevents users from making the informed decision to leave.
Fun stuff! See you next time. ;)
Member discussion